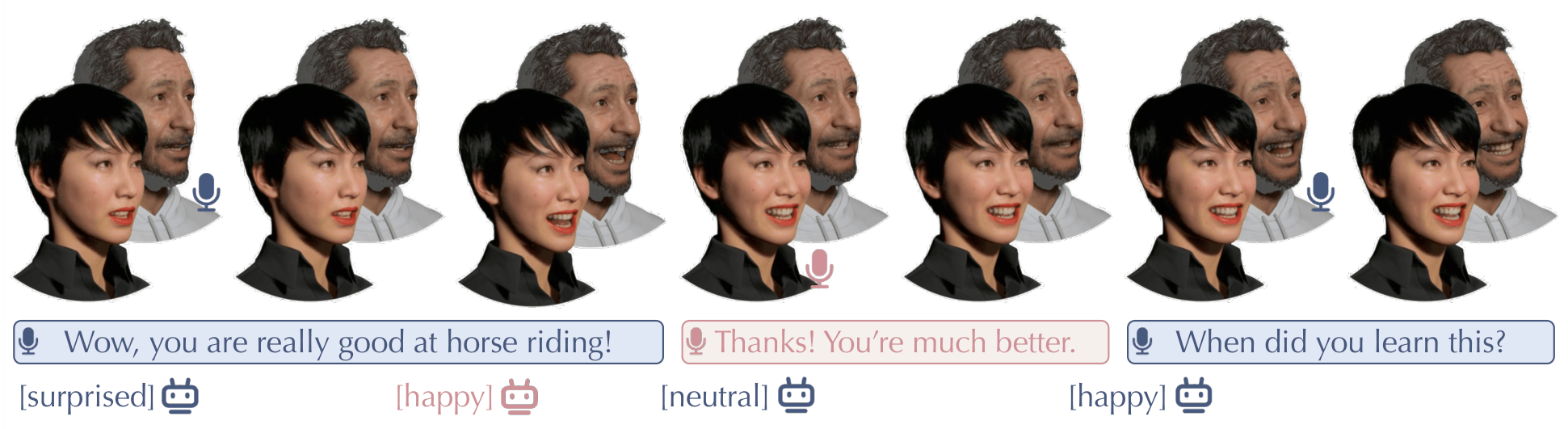
Grounded in the Ventral-Dorsal dual-pathway cognitive model, MindFlow introduces a framework for streaming facial animation in dyadic conversations, under which digital avatars simultaneously perceive conversational emotions while reflexively synchronizing with acoustic rhythms, naturally yielding interactions that are both semantically rich and physically fluid.